先に「URLは必ず表示されます」と書いたものの、表示されない場合があります。それが「フレーム」を使ったウェブページの場合です。○URLからわかること問題のウェブページをよく見てください。一つの窓が複数のフレーム(枠)に分割されているような感じがしますか? わかりにくければ、窓のどこかをスクロールしてみてください。その時にページ全体が動くのではなく、どこかは動かないままならば、そのページはフレームを使っています。また、リンク先をクリックして別のページにジャンプした時に、窓の一部だけが元のページのままという場合も同じくです。
こうした「フレーム」機能を使ったページでは、一つの窓の中でそれぞれ別個のURLを持ったページを同時に見せるようにしていますから、目的のページのURLは閲覧ソフトのURL表示欄には表示されない場合の方が多いです。
この場合は、当該ページだけをフレームから取り出す機能を使い、新たな窓を開いてからURLを確かめます。別ページ「中級テクニック」での説明を参考にしてください。
こうしてわかったURLからだけでもウェブページについてかなりの情報が手に入ります。そのウェブページが属しているサーバーの持ち主がわかったり、更にはウェブサイトの運営者名も推測がつくからです。これは検索エンジンでページのタイトルとURLしかわからない場合でも応用できます。○あなたの「ドメイン名」は相手に伝わるそこで、URLの仕組みについて最小限の説明をしておきます。
例えば…と、皆さんお馴染みの山大ウェブサイト玄関ページのURLを例に挙げます↓。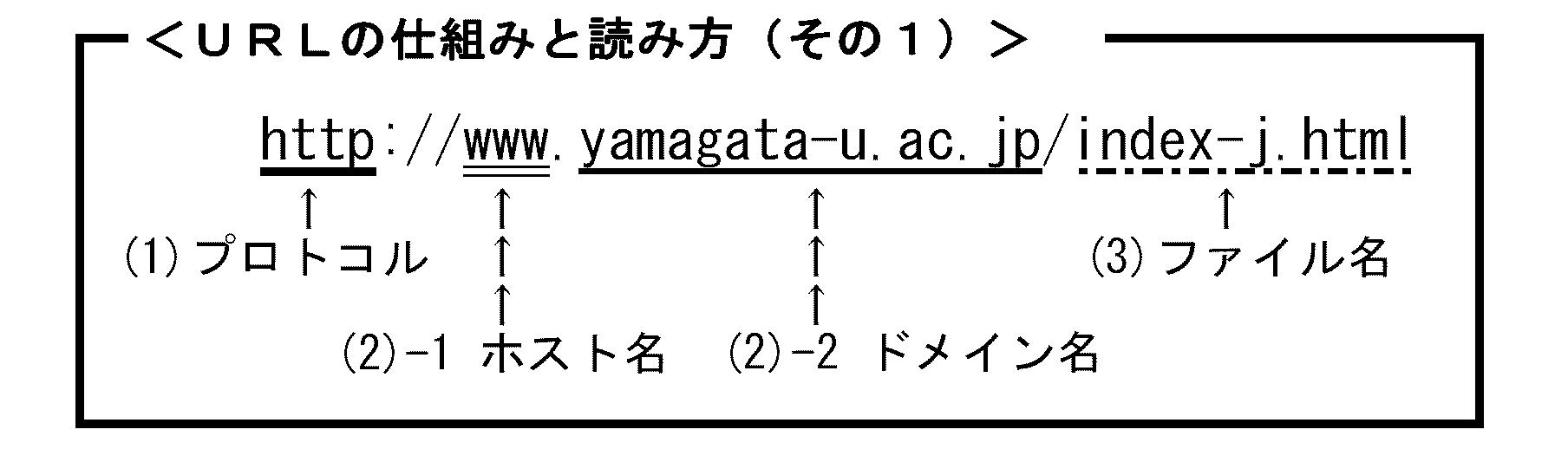 これが何を表しているのかというと、まずコロン「:」までの部分(http)はコンピュータ同士がデータを受け渡しする際の決まり(プロトコル)を指定するもので、この「http」の場合は「HyperText Transfer Protocol」を意味します。「HyperText」は別ページで説明したHTMLファイルの「HT」と同じで、「http」とはまさに“HTMLファイルをコンピュータ同士が受け渡しする際の決まり事”というわけです。
これが何を表しているのかというと、まずコロン「:」までの部分(http)はコンピュータ同士がデータを受け渡しする際の決まり(プロトコル)を指定するもので、この「http」の場合は「HyperText Transfer Protocol」を意味します。「HyperText」は別ページで説明したHTMLファイルの「HT」と同じで、「http」とはまさに“HTMLファイルをコンピュータ同士が受け渡しする際の決まり事”というわけです。そして次のスラッシュ二つ「//」の後ろから次のスラッシュまでの部分(www.yamagata-u.ac.jp)が、データが入っているコンピュータのインターネット内での居場所を表します。まず最初の「www」は,コンピュータ(サーバー)自体の名称で、これを「ホスト(host)名」と言います。インターネットに接続しているコンピュータは --- あなたの今使っているパソコンも --- すべて「ホストコンピュータ」と言います。次にこのホストコンピュータが属する組織の名称(「ドメイン(domain)名」)です。
さらに「ドメイン名」の次、スラッシュで区切ってから、そのコンピュータの中のどこに、求めるファイルがあるかどうかを示した上で、最後に,求めるファイルの名前「index-j.html」が示されます。
まとめると、以下のようになります。
(1) プロトコルは「HyperText Transfer Protocol」
(2)-1 ホスト名は「www」(「www」というホストコンピュータ)
(2)-2 ドメイン名は「yamagata-u.ac.jp」 ※以上二つをあわせて「完全なドメイン名」
(3) そこから自分のパソコンがもらってきて表示するファイル名「index-j.html」(B)ファイルのありか:パス名※ここで練習問題その3:山形大学のホストコンピュータ「www.yamagata-u.ac.jp」からあなたのコンピュータが「index-j.html」とは2字違いのファイル「index.html」をもらってくると、どんなページが表示されますか? 別ページ「トラブル対処法」で説明の「URL短縮法」を応用し、上記のURLhttp://www.yamagata-u.ac.jp/index-j.html--- の一部を書き換えて、実際にアクセスしてみましょう。そしてコンピュータの中身は「ディレクトリ」によって更に細かく区分けされます。そのコンピュータの中のどこに求めるファイルがあるのかを表すのが「パス名」です。ディレクトリのあるURLの例として、松本サイト玄関を挙げておきます↓。
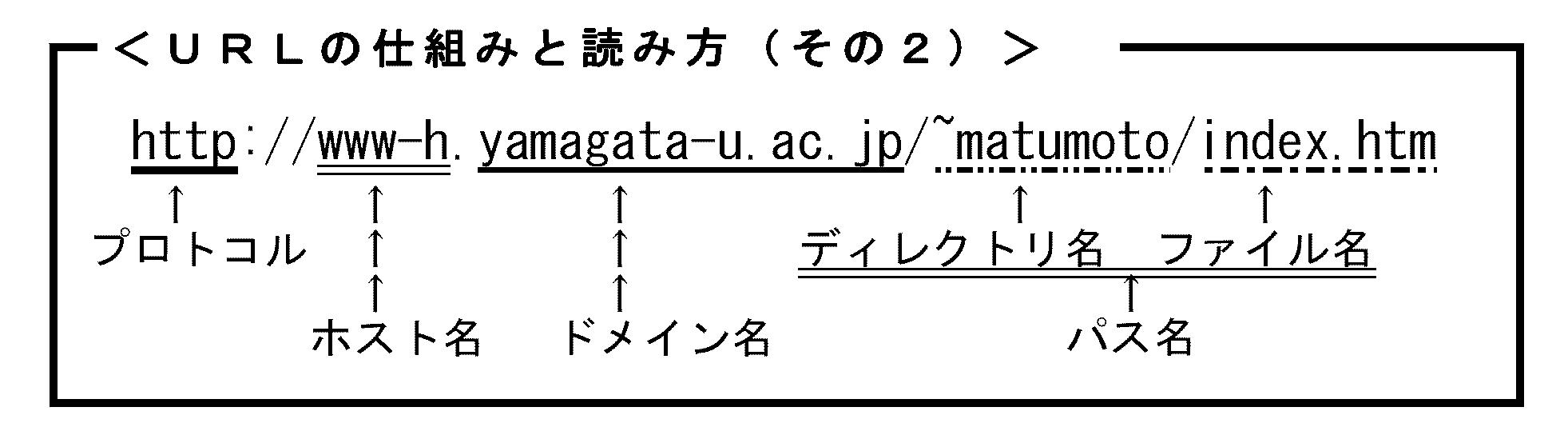 ※ここでも練習問題その4:上記の山大サイト玄関のURLとこの松本サイト玄関のURLとを見比べ、ホスト名とドメイン名の類似点、相違点をチェックしてください。このディレクトリを利用したトラブル解決法として別ページ「トラブル対処法」にて「URL短縮法」を紹介したとおり、ディレクトリはスラッシュ「/」を入れて右に右にと連ねていくことによって、更に細かいディレクトリに分けることができます。いわばビルの中の1階2階の区別のようなものです。そしてファイル名は同じでも、属するドメインやディレクトリさえ異なればコンピュータはそれぞれを別のものとして取り扱います。例えば「index.htm」は世界中のホストコンピュータの中に存在していますが、それぞれが別個のファイルなのです。ドメイン名を更に分割すると、右側からピリオド(ドットとも言う)で区切りつつ、「トップレベルドメイン」、「第2レベルドメイン」、「第3レベルドメイン」と呼びます(↓。「第4」「第5」もある)。そしてその組織の特徴を表すのが「トップ」と「第2」です。
※ここでも練習問題その4:上記の山大サイト玄関のURLとこの松本サイト玄関のURLとを見比べ、ホスト名とドメイン名の類似点、相違点をチェックしてください。このディレクトリを利用したトラブル解決法として別ページ「トラブル対処法」にて「URL短縮法」を紹介したとおり、ディレクトリはスラッシュ「/」を入れて右に右にと連ねていくことによって、更に細かいディレクトリに分けることができます。いわばビルの中の1階2階の区別のようなものです。そしてファイル名は同じでも、属するドメインやディレクトリさえ異なればコンピュータはそれぞれを別のものとして取り扱います。例えば「index.htm」は世界中のホストコンピュータの中に存在していますが、それぞれが別個のファイルなのです。ドメイン名を更に分割すると、右側からピリオド(ドットとも言う)で区切りつつ、「トップレベルドメイン」、「第2レベルドメイン」、「第3レベルドメイン」と呼びます(↓。「第4」「第5」もある)。そしてその組織の特徴を表すのが「トップ」と「第2」です。 まず山大ウェブサイト玄関URLの「トップレベルドメイン」の「jp」は「国別トップレベルドメイン」と言い、「Japan」つまり日本という国名を表します。同様に諸外国の国名も二文字で表され、韓国は Koreaの「kr」、オーストラリアは「au」です。もっとも「http://home.netscape.com」のように「一般トップレベルドメイン」としての「com」(商業組織)や「net」(ネットワーク活動組織)を用いるドメインもあります。
まず山大ウェブサイト玄関URLの「トップレベルドメイン」の「jp」は「国別トップレベルドメイン」と言い、「Japan」つまり日本という国名を表します。同様に諸外国の国名も二文字で表され、韓国は Koreaの「kr」、オーストラリアは「au」です。もっとも「http://home.netscape.com」のように「一般トップレベルドメイン」としての「com」(商業組織)や「net」(ネットワーク活動組織)を用いるドメインもあります。そして「第2レベルドメイン」ですが、これでだいたい組織の性格がわかるようになっています。こういう具合です↓。
この“推測”は、ウェブページを表示させる前にする方が役立ちます。検索エンジンで検索結果が表示された際に、いちいち見に行かずともページの性格をチェックできるからです。
- 「ac」は academy つまり大学など学術団体、教育団体
- http://www.trc.co.jp ---- の「co」は company 商業組織
- http://www.kantei.go.jp ---- の「go」は government 政府機関(「gov」の場合はトップレベルドメインで、アメリカ政府機関用)
なお皆さん自身もインターネットではドメインを使っていることを自覚していてください。それはインターネットの仕組みが、(実は)放送局が不特定多数にデータを送る“放送”(誰が放送を見て・聞いているのかはわからない)ではなく、特定の相手とデータをやりとりする“電話”に近いからです。もっとも(見かけ上は)同時に何人もの相手と会話ができる点は電話とは大きく違いますが。あなたが特定のウェブサイトにアクセスした場合、そのサイトのページのファイルを貯蔵しているホストコンピュータ(サーバー)は、あなたの使っているホストコンピュータ(サーバーに対してこれを「クライアント client」と言う)からの要求に応えて、あなたのコンピュータにページのデータを送ってきます(その際の決まり事が上記「コンピュータの居所」に登場した「http」)。この二つのホストコンピュータは、お互いの相手をどう特定するのか? ドメイン名と同時に、“コンピュータ同士だけで分かる符丁”つまり「IPアドレス」という無味乾燥な数字の羅列で特定します。
よって、大学の共用パソコンでアクセスした場合、アクセスの相手は自分のコンピュータ(サーバー)に残ったアクセス記録(log)を見ることで,“○○大学からインターネットエクスプローラを使ってアクセスしてきたな”とわかりますし、自宅のパソコンからプロパイダーを通した場合はプロパイダーが使っているホストコンピュータのドメイン名とIPアドレスが相手に伝わります。つまりネット世界でも完全な匿名というのはありえないのです。これを悪用した詐欺が通称“ワンクリック詐欺”(最近では“ツークリック詐欺”)であり、松本が体験した実例を別ページ「アクセスだけで伝わるあなたの情報」に紹介していますので一読してください。
※アクセスログを記録していることを明示しているウェブサイトの例↓(他のウェブサイトも、明示はしていなくても記録はしていると見て良い。)また、サーバーとあなたのコンピュータ(クライアント)とのやりとりは一対一でおこなわれるわけではなく、いくつものホストコンピュータが仲立ちをします。つまり途中での“覗き見”が可能です。たとえばメールでも、会社内で上司が部下のメールの内容を読むことも可能なわけです(私用メールの有無や社外秘情報の漏洩チェックなど)。(社)コンピュータソフトウェア著作権協会
http://www2.accsjp.or.jp/
>著作権・セキュリティについて
http://www2.accsjp.or.jp/policy/in_policy.htmlよって、ハガキにあなたが内緒事を書かないように、オンラインショッピングでクレジットカードの番号を入力する時には「暗号」機能が必要になるわけですが、そちらは本書では略します。別ページ「電子時代の倫理とマナー」で紹介した参考書を読んでください。